
Understanding the Nuts and Bolts of Convolutional Neural Networks: Insights and from-scratch implementation using PyTorch - Part 2.
Published:
This post provides an in-depth understanding of Convolutional Neural Networks (CNNs), detailed insights into bedrock operations that power CNNs and step-by-step implementation using PyTorch.
Introduction:
Convolutional Neural Networks (CNNs) are deep learning models designed to automatically and adaptively learn spatial hierarchies of features within images for tasks like classification, detection, and segmentation. In the “previous post” we studied the theoretical concepts and the different types of layers a typical CNN might contain. In this post, we shall do a from-scratch implementation of the Convolutional Neural Network using PyTorch for image classification using following steps.
- Download and Normalize the datasets
- Define the Convolutional Neural Network
- Define the model, loss function, and optimization algorithm
- Train the model on the training dataset
- Validate the model using training dataset
- Validate the model using testing dataset
- Early stopping the model training
- Visualize the model training process
- Load the trained model and apply to general data
1. Download and Normalize the datasets:
Let us download and use the CIFAR10 dataset, a well-known computer vision and machine learning dataset used to study and benchmark CNN for Image Classification. CIFAR-10 stands for the “Canadian Institute for Advanced Research,” and “10” refers to the number of classes in the dataset. The dataset consists of 60,000 color images, each with a size of 32x32 pixels. There are ten different classes, each representing a specific object or category. The classes are: [Airplane, Automobile, Bird, Cat, Deer, Dog, Frog, Horse, Ship, Truck]. The images in CIFAR-10 are relatively low-resolution, each being 32x32 pixels in size. The dataset is divided into two subsets: a training set containing 50,000 images and a testing set with 10,000 images.
Once we download the dataset, we need to normalize it since it ensures uniformity in feature scales, aiding generalization by making the model less sensitive to variations in input data for effective CNN model training. Along with normalization, we must convert image formats into PyTorch tensors, a fundamental data format for neural networks, enabling efficient computation and GPU utilization.
So, we will build a transformation to convert images into multi-dimensional tensors while normalizing pixel values with a mean and standard deviation of 0.5 across all three channels for both the training and testing datasets.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./dataset/cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [00:02<00:00, 76927252.68it/s]
Extracting ./dataset/cifar-10-python.tar.gz to ./dataset
Files already downloaded and verified
PyTorch employs dataloader functionality with “torch.utils.data.DataLoader” which encapsulates the training/testing dataset and defines a DataLoader (train/testloader) that manages the data in batches, specifically with defined batch size samples. Batching allows for more efficient processing, as the model updates its parameters based on these batches rather than individual data points, improving computational speed and memory usage. The shuffle=True argument randomizes the order of samples within each batch, ensuring that the model does not learn from the sequence of data and instead generalizes better by being exposed to varied samples in each iteration.
Now, we shall also try to visualize the training images to see how the images from the CIFAR10 dataset would look like.
The total number of images loaded per batch are 128, and the shape of each image is torch.Size([3, 32, 32])

The label name of the displayed image is car
2. Define the Convolutional Neural Network:
To define the Convolutional Neural Network, we inherit the “nn.Module” class in PyTorch, which is a fundamental building block for creating neural network architectures. The nn.Module enables users to define and organize layers, parameters, and operations of a neural network in a structured and modular manner. The class that we use to define the CNN will have two methods:
1. __init__ method: The __init__ is a constructor method for initializing neural network architectures in PyTorch. Here, we initialize and define the various network layers like convolutional, pooling, and fully connected layers that will be used to construct the neural network architecture. Parameters of these layers, such as weights and biases, are automatically registered and tracked by PyTorch. In total, this method acts like a structured foundation for the forward pass method (forward) to process input data through the defined layers.
2. Forward method: This method specifies the sequence of operations/layers defined in the init method to control how the input data flows through the network layers, allowing PyTorch to compute the output during the forward propagation. In this method, the input tensor moves through each layer, undergoing layers defined in the __init__ such as convolutions, activations, pooling, and linear transformations. By applying these operations sequentially, the network progressively extracts hierarchical representations from the input data, enabling the model to generate predictions or produce meaningful output.
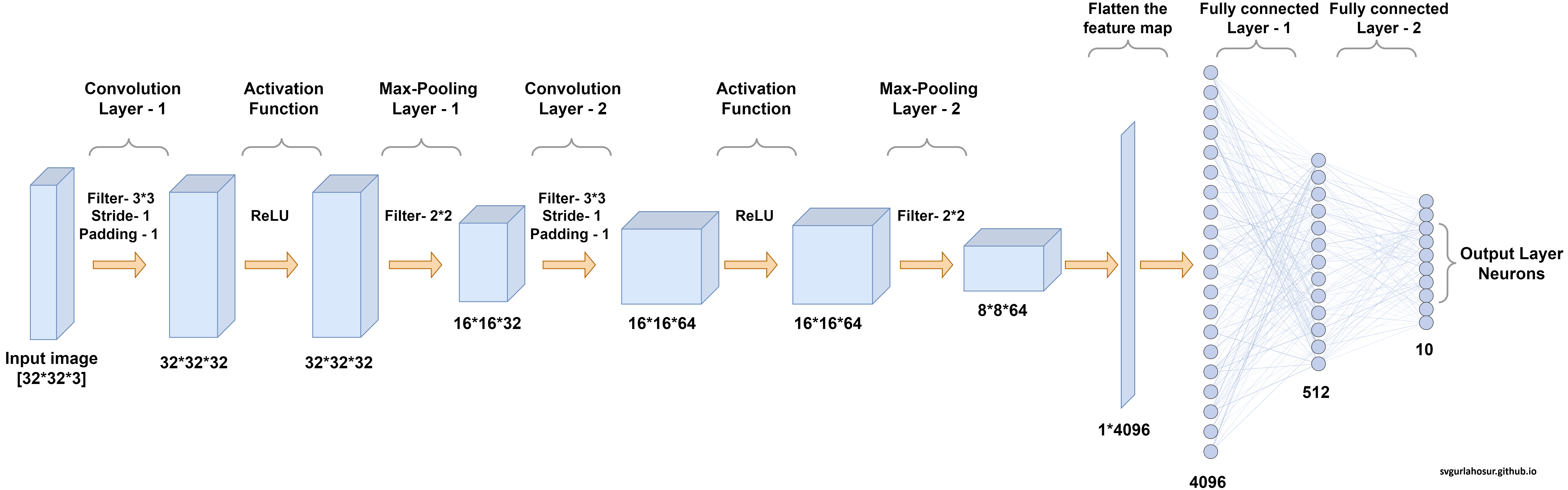
Let us consider the CNN architecture shown in Figure 1 and define a class to represent it. To implement the architecture, let us understand the organization of layers in the architecture.
- Input Layer:
- The network takes an input with three channels (CIFAR10-dataset RGB images).
- Convolutional Layers:
- The first convolutional layer has three input channels, 32 output channels, and a kernel size of 3x3. The padding is set to 1, meaning the spatial dimensions of the output feature map will be the same as the input.
- The second convolutional layer has 32 input channels, 64 output channels, and a kernel size of 3x3. Similar to the first layer, it has a padding of 1. Identical to the first convolution layer, the spatial dimensions of the output feature map will be the same as the input.
- Pooling Layer:
- Max pooling layer with a kernel size of 2x2 and a stride of 2. It reduces the spatial dimensions of the feature maps by half.
- Fully Connected Layers (Dense Layers):
- The first fully connected layer has 6488 input features and 512 output features. The input size is calculated based on the spatial dimensions of the feature maps after the convolutional and pooling layers.
- The final fully connected layer has 512 input features and 10 output features corresponding to the number of classes in the classification task.
- Activation Function:
- ReLU (Rectified Linear Unit) activation function is applied after each convolutional layer and the first fully connected layer.
Let us create a class named Network that inherits from nn.Module, the base class for all neural network modules in PyTorch. Next, we initialize the class constructor __init__ to define the constructor method for the Network class and call the superclass’s constructor (nn.Module) to initialize the base class properly. In the __init__ method, we define various layers that will be used to construct the Convolutional Neural Network, and the forward method specifies the sequence of layers/operations defined in the init method to control how the input data flows through the network layers.
Let us define the convolutional layers of the network using the nn.Conv2d function, which is a class in PyTorch that represents a 2-dimensional convolutional layer.
- The first convolutional layer (self.conv1) will be defined with:
- Input channels: 3 (for RGB images)
- Output channels: 32
- Kernel size: 3x3
- Padding: 1 (to maintain spatial dimensions)
- The second convolutional layer (self.conv2) will be defined with:
- Input channels: 32 (output from the previous layer)
- Output channels: 64
- Kernel size: 3x3
- Padding: 1 (to maintain spatial dimensions)
Let us define the pooling layer using the nn.MaxPool2d function, which is a class in PyTorch that represents a 2-dimensional max pooling layer.
- The max pooling layer (self.pool) will be defined with:
- Kernel size: 2x2
- Stride: 2 (downsampling by a factor of 2)
Finally, we will define the fully connected layers using the nn.Linear function, which is a class in PyTorch that represents a linear transformation, is commonly known as a fully connected or dense layer.
- The first fully connected layer (self.fc1) will be defined with:
- Input features: 64 * 8 * 8 (output from the second convolutional layer)
- Output features: 512
- The second fully connected layer (self.fc2) will be defined with:
- Input features: 512 (output from the first fully connected layer)
- Output features: 10 (number of classes)
Now, we shall define the forward method to implement the forward pass for the network. This method defines how the input tensor moves through each layer, defined in the __init__ method.
- The first convolution block is organized as follows:
- Apply the first convolutional layer (self.conv1) to the input (x).
- Apply the ReLU activation function (F.relu) to feature maps from self.conv1.
- Perform max pooling (self.pool) on output from F.relu.
- The second convolution block is organized as follows:
- Apply the second convolutional layer (self.conv2) to the previous convolutional layer block result.
- Apply the ReLU activation function (F.relu) to feature maps from self.conv2.
- Perform max pooling (self.pool) on output from F.relu.
- Reshape the feature maps from the second convolution block to prepare for the fully connected layers.
- The fully connected layers are arranged as follows:
- Apply the first fully connected layer (self.fc1) to the reshaped feature map, followed by the ReLU activation (F.relu).
- Apply the second fully connected layer (self.fc2) on output from F.relu and return the feature maps as network output.
3. Define the model, loss function, and optimization algorithm
Now, we shall create an instance/object of a class Network as model representing the neural network architecture, such as the number of layers, types of layers, initial weights, bias, and kernel/filter values for all the layers.
Then we use “nn.CrossEntropyLoss()” loss function to create a variable criterion. The Cross-Entropy Loss is commonly used for classification problems where the goal is to minimize the difference between predicted class probabilities and the true class labels. We also create an instance of the Adam optimizer for updating the model’s parameters during training to minimize the defined loss with a learning rate of 0.001.
Finally, we check for the availability of a GPU, and if a GPU is available, the device is set to “cuda”; otherwise, it defaults to “cpu” and moves the entire net model to the specified device. If a GPU is available, this step enables the model to leverage GPU acceleration during training, significantly speeding up the computations.
4. Train the model using training dataset
Once we have created the CNN model for the class Network, the model will have initial values for weights, bias, and kernel/filter for all the layers, and this model cannot be used directly to do the image classification task. Hence, we need to optimize its parameters and enable it to learn patterns and representations inherent in the dataset. So, we iteratively expose the model to diverse examples, allow the model to predict the output, and then allow it to adjust its parameters through backpropagation.
So, we shall create a loop for a specified number of epochs, and within each epoch, a nested loop iterates over batches of data (images and labels) from the trainloader. The images are given as input to the model and to produce predictions (outputs). The error between these predictions and the actual labels is computed using the loss function, which is then backpropagated through the network. The optimizer adjusts the model’s weights based on the calculated gradients during backpropagation. The optimization of model parameters will minimize the discrepancy(error) between predicted and actual output, and the model gradually improves its ability to generalize to unseen data. During each iteration, we also clear the accumulated gradients from the previous iteration to ensure a fresh start for computing gradients in the current iteration, preventing accidental gradient accumulation and allowing accurate parameter updation during optimization. The cumulative loss for the epoch is stored in a list, which serves as a record of the training loss progression, capturing the model’s learning dynamics throughout the model training.
5. Validate the model using training dataset
During each epoch, along with training the model using the training dataset, we shall first validate model performance on the training dataset it was trained on before validating it on the unseen testing dataset. So, we will calculate the following metrics to get insights into different aspects of the model learning ability.
Top-1 Accuracy: Measure the percentage of training examples for which the model’s top predicted output matches the actual output.
Top-5 Accuracy: Measure the percentage of predictions where the actual output may not be the top predicted output but is within the top 5 predicted output.
Per-Class Top-1 Accuracy: Measure the Top-1 accuracy for model performance on each class within the dataset.
6. Validate the model using testing dataset
During each epoch, along with training the model, we shall validate model performance on the unseen testing dataset. So, we will calculate the same set of metrics we calculated to validate the performance of the the model on the training dataset.
7. Early stopping the model training
During the training loop, at every epoch during the model training, we optimize the model parameters and validate the model performance on both the training and testing datasets so that we will have the optimized model with the best performance at the end of all the epochs. But sometimes, it is unnecessary to complete all the epochs and we may have stopped the training early without completing all the epochs.
The early stopping mechanism is crucial in training machine learning models for various compelling reasons. Firstly, it is a critical mechanism to prevent overfitting by closely monitoring the validation loss. It stops the model training when the loss for testing data starts shooting up or sometimes not decreasing, ensuring that the model does not become overly specialized to the training dataset. Since training deep learning models is resource-intensive, terminating the training process when further improvement is unlikely can substantially reduce the overall computational burden.
Let us implement an early stopping mechanism by monitoring the testing loss during the model training process. Suppose the current testing loss is lower than the best testing loss observed so far; the best testing loss is updated, and the current model is saved. Suppose there is no improvement in testing loss for a specified number of consecutive epochs, indicating that the model performance on the testing set has not improved. In that case, the training loop is halted by printing the appropriate message.
Now, let us train the model and see the model performance on training and testing datasets. The code for the complete model training loop looks as follows.
0%| | 0/40 [00:00<?, ?it/s]
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 1 is: 862.1533234119415
The training top-1, top-5 accuracy for the epoch 1 are: 25.714 % & 75.63 %
-------------------------------------------------------------Testing-------------------------------------------------------------
2%|▎ | 1/40 [00:53<34:54, 53.70s/it]
The testing loss for the epoch 1 is: 162.34049999713898
The testing top-1, top-5 accuracy for the epoch 1 are: 26.54% & 76.11%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 2 is: 764.9626425504684
The training top-1, top-5 accuracy for the epoch 2 are: 35.59 % & 84.01 %
-------------------------------------------------------------Testing-------------------------------------------------------------
5%|▌ | 2/40 [01:35<29:32, 46.65s/it]
The testing loss for the epoch 2 is: 144.09120738506317
The testing top-1, top-5 accuracy for the epoch 2 are: 36.16% & 84.35%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 3 is: 686.0798470973969
The training top-1, top-5 accuracy for the epoch 3 are: 40.758 % & 88.04 %
-------------------------------------------------------------Testing-------------------------------------------------------------
8%|▊ | 3/40 [02:10<25:26, 41.25s/it]
The testing loss for the epoch 3 is: 131.85812437534332
The testing top-1, top-5 accuracy for the epoch 3 are: 41.0% & 88.08%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 4 is: 629.2317101955414
The training top-1, top-5 accuracy for the epoch 4 are: 45.106 % & 90.79 %
-------------------------------------------------------------Testing-------------------------------------------------------------
10%|█ | 4/40 [02:44<23:06, 38.51s/it]
The testing loss for the epoch 4 is: 121.47322475910187
The testing top-1, top-5 accuracy for the epoch 4 are: 45.28% & 90.52%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 5 is: 583.997419834137
The training top-1, top-5 accuracy for the epoch 5 are: 48.108 % & 92.18 %
-------------------------------------------------------------Testing-------------------------------------------------------------
12%|█▎ | 5/40 [03:18<21:34, 36.98s/it]
The testing loss for the epoch 5 is: 114.85044312477112
The testing top-1, top-5 accuracy for the epoch 5 are: 47.81% & 91.99%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 6 is: 551.3813041448593
The training top-1, top-5 accuracy for the epoch 6 are: 51.168 % & 93.34 %
-------------------------------------------------------------Testing-------------------------------------------------------------
15%|█▌ | 6/40 [03:52<20:24, 36.02s/it]
The testing loss for the epoch 6 is: 107.9937469959259
The testing top-1, top-5 accuracy for the epoch 6 are: 51.08% & 93.50%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 7 is: 526.0367250442505
The training top-1, top-5 accuracy for the epoch 7 are: 53.616 % & 94.14 %
-------------------------------------------------------------Testing-------------------------------------------------------------
18%|█▊ | 7/40 [04:27<19:35, 35.61s/it]
The testing loss for the epoch 7 is: 103.40667033195496
The testing top-1, top-5 accuracy for the epoch 7 are: 53.17% & 94.04%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 8 is: 506.457279086113
The training top-1, top-5 accuracy for the epoch 8 are: 55.574 % & 94.71 %
-------------------------------------------------------------Testing-------------------------------------------------------------
20%|██ | 8/40 [05:01<18:43, 35.12s/it]
The testing loss for the epoch 8 is: 100.64028811454773
The testing top-1, top-5 accuracy for the epoch 8 are: 54.98% & 94.64%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 9 is: 487.6429954171181
The training top-1, top-5 accuracy for the epoch 9 are: 56.238 % & 94.93 %
-------------------------------------------------------------Testing-------------------------------------------------------------
22%|██▎ | 9/40 [05:35<17:56, 34.72s/it]
The testing loss for the epoch 9 is: 99.342529296875
The testing top-1, top-5 accuracy for the epoch 9 are: 54.57% & 95.00%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 10 is: 472.83003824949265
The training top-1, top-5 accuracy for the epoch 10 are: 58.884 % & 95.49 %
-------------------------------------------------------------Testing-------------------------------------------------------------
25%|██▌ | 10/40 [06:09<17:10, 34.34s/it]
The testing loss for the epoch 10 is: 94.58817684650421
The testing top-1, top-5 accuracy for the epoch 10 are: 57.19% & 95.53%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 11 is: 456.7414014339447
The training top-1, top-5 accuracy for the epoch 11 are: 60.256 % & 95.70 %
-------------------------------------------------------------Testing-------------------------------------------------------------
28%|██▊ | 11/40 [06:42<16:31, 34.18s/it]
The testing loss for the epoch 11 is: 92.22701132297516
The testing top-1, top-5 accuracy for the epoch 11 are: 59.12% & 95.38%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 12 is: 443.82007044553757
The training top-1, top-5 accuracy for the epoch 12 are: 61.548 % & 95.98 %
-------------------------------------------------------------Testing-------------------------------------------------------------
30%|███ | 12/40 [07:16<15:55, 34.12s/it]
The testing loss for the epoch 12 is: 90.08219343423843
The testing top-1, top-5 accuracy for the epoch 12 are: 59.58% & 96.07%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 13 is: 431.5397505760193
The training top-1, top-5 accuracy for the epoch 13 are: 62.758 % & 96.18 %
-------------------------------------------------------------Testing-------------------------------------------------------------
32%|███▎ | 13/40 [07:50<15:15, 33.91s/it]
The testing loss for the epoch 13 is: 87.97439712285995
The testing top-1, top-5 accuracy for the epoch 13 are: 60.25% & 96.08%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 14 is: 420.6241260766983
The training top-1, top-5 accuracy for the epoch 14 are: 62.814 % & 96.43 %
-------------------------------------------------------------Testing-------------------------------------------------------------
35%|███▌ | 14/40 [08:23<14:38, 33.80s/it]
The testing loss for the epoch 14 is: 87.83500701189041
The testing top-1, top-5 accuracy for the epoch 14 are: 60.54% & 96.09%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 15 is: 408.51489758491516
The training top-1, top-5 accuracy for the epoch 15 are: 63.942 % & 96.34 %
-------------------------------------------------------------Testing-------------------------------------------------------------
38%|███▊ | 15/40 [08:57<14:04, 33.76s/it]
The testing loss for the epoch 15 is: 86.63428193330765
The testing top-1, top-5 accuracy for the epoch 15 are: 61.12% & 95.90%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 16 is: 397.38445073366165
The training top-1, top-5 accuracy for the epoch 16 are: 65.326 % & 96.83 %
-------------------------------------------------------------Testing-------------------------------------------------------------
40%|████ | 16/40 [09:32<13:36, 34.03s/it]
The testing loss for the epoch 16 is: 84.54809135198593
The testing top-1, top-5 accuracy for the epoch 16 are: 61.98% & 96.43%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 17 is: 387.7873947620392
The training top-1, top-5 accuracy for the epoch 17 are: 66.608 % & 96.98 %
-------------------------------------------------------------Testing-------------------------------------------------------------
42%|████▎ | 17/40 [10:06<13:06, 34.21s/it]
The testing loss for the epoch 17 is: 82.03651577234268
The testing top-1, top-5 accuracy for the epoch 17 are: 63.3% & 96.35%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 18 is: 377.16318732500076
The training top-1, top-5 accuracy for the epoch 18 are: 68.152 % & 97.26 %
-------------------------------------------------------------Testing-------------------------------------------------------------
45%|████▌ | 18/40 [10:41<12:33, 34.27s/it]
The testing loss for the epoch 18 is: 79.92197495698929
The testing top-1, top-5 accuracy for the epoch 18 are: 64.88% & 96.72%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 19 is: 366.98551404476166
The training top-1, top-5 accuracy for the epoch 19 are: 69.03 % & 97.42 %
-------------------------------------------------------------Testing-------------------------------------------------------------
48%|████▊ | 19/40 [11:14<11:55, 34.07s/it]
The testing loss for the epoch 19 is: 78.62003481388092
The testing top-1, top-5 accuracy for the epoch 19 are: 65.16% & 96.75%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 20 is: 357.0173394680023
The training top-1, top-5 accuracy for the epoch 20 are: 69.544 % & 97.37 %
-------------------------------------------------------------Testing-------------------------------------------------------------
50%|█████ | 20/40 [11:52<11:41, 35.07s/it]
The testing loss for the epoch 20 is: 79.16529422998428
The testing top-1, top-5 accuracy for the epoch 20 are: 64.9% & 96.49%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 21 is: 348.62181174755096
The training top-1, top-5 accuracy for the epoch 21 are: 69.926 % & 97.65 %
-------------------------------------------------------------Testing-------------------------------------------------------------
52%|█████▎ | 21/40 [12:31<11:29, 36.28s/it]
The testing loss for the epoch 21 is: 78.21170526742935
The testing top-1, top-5 accuracy for the epoch 21 are: 65.13% & 96.94%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 22 is: 339.0841175317764
The training top-1, top-5 accuracy for the epoch 22 are: 71.602 % & 97.86 %
-------------------------------------------------------------Testing-------------------------------------------------------------
55%|█████▌ | 22/40 [13:05<10:41, 35.65s/it]
The testing loss for the epoch 22 is: 75.91331839561462
The testing top-1, top-5 accuracy for the epoch 22 are: 66.57% & 97.01%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 23 is: 328.90890741348267
The training top-1, top-5 accuracy for the epoch 23 are: 72.686 % & 98.05 %
-------------------------------------------------------------Testing-------------------------------------------------------------
57%|█████▊ | 23/40 [13:39<09:55, 35.05s/it]
The testing loss for the epoch 23 is: 74.67213398218155
The testing top-1, top-5 accuracy for the epoch 23 are: 66.9% & 97.11%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 24 is: 319.597803235054
The training top-1, top-5 accuracy for the epoch 24 are: 72.868 % & 98.07 %
-------------------------------------------------------------Testing-------------------------------------------------------------
60%|██████ | 24/40 [14:14<09:20, 35.06s/it]
The testing loss for the epoch 24 is: 75.23766601085663
The testing top-1, top-5 accuracy for the epoch 24 are: 66.94% & 97.06%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 25 is: 312.0265933871269
The training top-1, top-5 accuracy for the epoch 25 are: 74.282 % & 98.22 %
-------------------------------------------------------------Testing-------------------------------------------------------------
62%|██████▎ | 25/40 [14:51<08:55, 35.68s/it]
The testing loss for the epoch 25 is: 74.01538652181625
The testing top-1, top-5 accuracy for the epoch 25 are: 67.33% & 97.16%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 26 is: 301.0282014608383
The training top-1, top-5 accuracy for the epoch 26 are: 74.946 % & 98.40 %
-------------------------------------------------------------Testing-------------------------------------------------------------
65%|██████▌ | 26/40 [15:25<08:13, 35.27s/it]
The testing loss for the epoch 26 is: 73.3805941939354
The testing top-1, top-5 accuracy for the epoch 26 are: 67.73% & 97.19%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 27 is: 291.712499499321
The training top-1, top-5 accuracy for the epoch 27 are: 75.46 % & 98.43 %
-------------------------------------------------------------Testing-------------------------------------------------------------
68%|██████▊ | 27/40 [16:00<07:35, 35.02s/it]
The testing loss for the epoch 27 is: 73.38452762365341
The testing top-1, top-5 accuracy for the epoch 27 are: 67.36% & 97.38%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 28 is: 283.04075318574905
The training top-1, top-5 accuracy for the epoch 28 are: 75.242 % & 98.45 %
-------------------------------------------------------------Testing-------------------------------------------------------------
70%|███████ | 28/40 [16:34<06:59, 34.95s/it]
The testing loss for the epoch 28 is: 74.87867146730423
The testing top-1, top-5 accuracy for the epoch 28 are: 67.3% & 97.17%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 29 is: 274.3129668533802
The training top-1, top-5 accuracy for the epoch 29 are: 77.566 % & 98.67 %
-------------------------------------------------------------Testing-------------------------------------------------------------
72%|███████▎ | 29/40 [17:08<06:21, 34.67s/it]
The testing loss for the epoch 29 is: 71.01980268955231
The testing top-1, top-5 accuracy for the epoch 29 are: 69.0% & 97.45%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 30 is: 265.73878276348114
The training top-1, top-5 accuracy for the epoch 30 are: 79.042 % & 98.80 %
-------------------------------------------------------------Testing-------------------------------------------------------------
75%|███████▌ | 30/40 [17:44<05:48, 34.85s/it]
The testing loss for the epoch 30 is: 70.19548535346985
The testing top-1, top-5 accuracy for the epoch 30 are: 69.02% & 97.51%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 31 is: 254.14276725053787
The training top-1, top-5 accuracy for the epoch 31 are: 79.444 % & 98.91 %
-------------------------------------------------------------Testing-------------------------------------------------------------
78%|███████▊ | 31/40 [18:18<05:11, 34.59s/it]
The testing loss for the epoch 31 is: 70.609494805336
The testing top-1, top-5 accuracy for the epoch 31 are: 69.28% & 97.52%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 32 is: 245.0979337990284
The training top-1, top-5 accuracy for the epoch 32 are: 79.406 % & 98.85 %
-------------------------------------------------------------Testing-------------------------------------------------------------
80%|████████ | 32/40 [18:52<04:35, 34.45s/it]
The testing loss for the epoch 32 is: 72.33375650644302
The testing top-1, top-5 accuracy for the epoch 32 are: 69.05% & 97.35%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 33 is: 237.57554629445076
The training top-1, top-5 accuracy for the epoch 33 are: 81.074 % & 99.06 %
-------------------------------------------------------------Testing-------------------------------------------------------------
82%|████████▎ | 33/40 [19:26<04:00, 34.31s/it]
The testing loss for the epoch 33 is: 70.61394441127777
The testing top-1, top-5 accuracy for the epoch 33 are: 69.41% & 97.43%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 34 is: 227.79885429143906
The training top-1, top-5 accuracy for the epoch 34 are: 82.118 % & 99.14 %
-------------------------------------------------------------Testing-------------------------------------------------------------
85%|████████▌ | 34/40 [20:00<03:25, 34.24s/it]
The testing loss for the epoch 34 is: 70.81468188762665
The testing top-1, top-5 accuracy for the epoch 34 are: 69.84% & 97.58%
----------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------Training-------------------------------------------------------------
The training loss for the epoch 35 is: 217.21909826993942
The training top-1, top-5 accuracy for the epoch 35 are: 81.236 % & 99.16 %
-------------------------------------------------------------Testing-------------------------------------------------------------
85%|████████▌ | 34/40 [20:34<03:37, 36.30s/it]
The testing loss for the epoch 35 is: 73.7378540635109
The testing top-1, top-5 accuracy for the epoch 35 are: 69.0% & 97.45%
----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------
Early stopping the model training after 5 epochs of no improvement in testing loss
----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------
The best model is obtained at epoch: 30 with Top-1 accuracy of: 69.02 % and model is saved with name: epoch_30_accuarcy_69.02.pth
----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------
8. Visualize the model training process through graphs
Once the model is trained, we shall do a graphical visualization of various metrics used to evaluate the model performance. The visualization serves as an effective way to understand the training progress and final model performance.
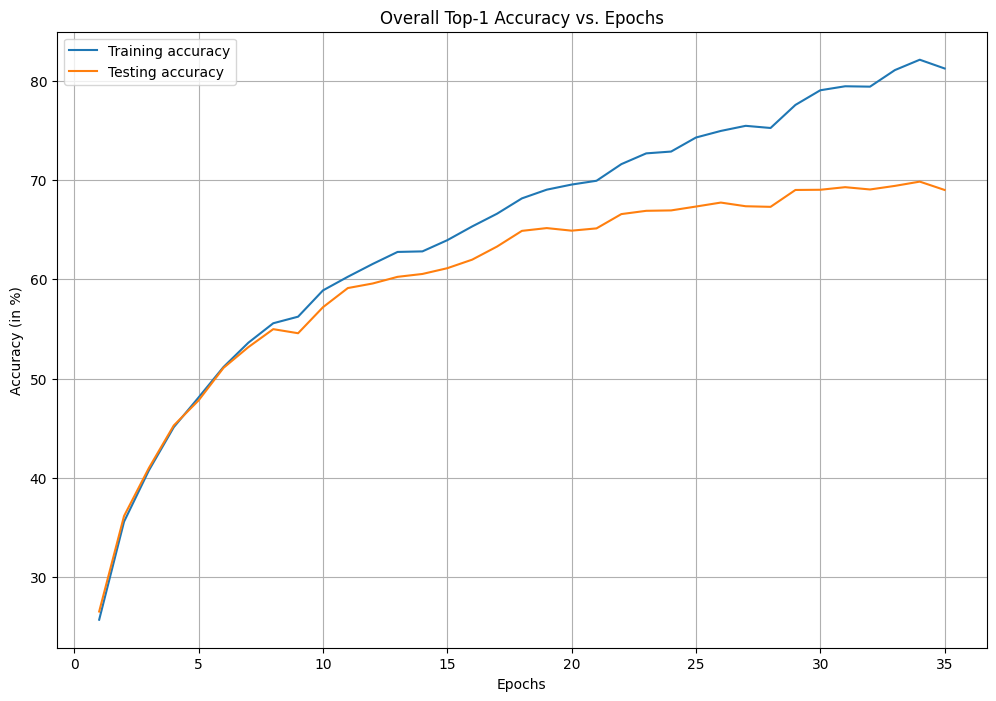
i. Let us plot a graph to illustrate the progression of training and testing Top-1 accuracy throughout the model training epochs to get insights into its learning and generalization ability.
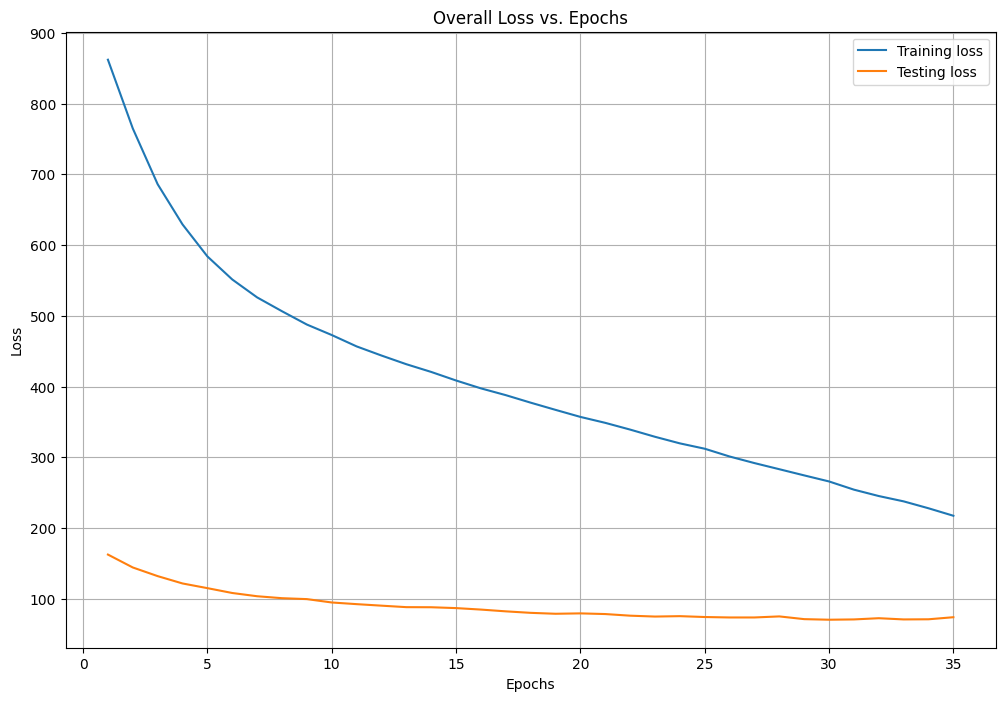
ii. Let us plot a graph to illustrate the progression of training and testing loss throughout the model training epochs to get insights into its learning and generalization ability.
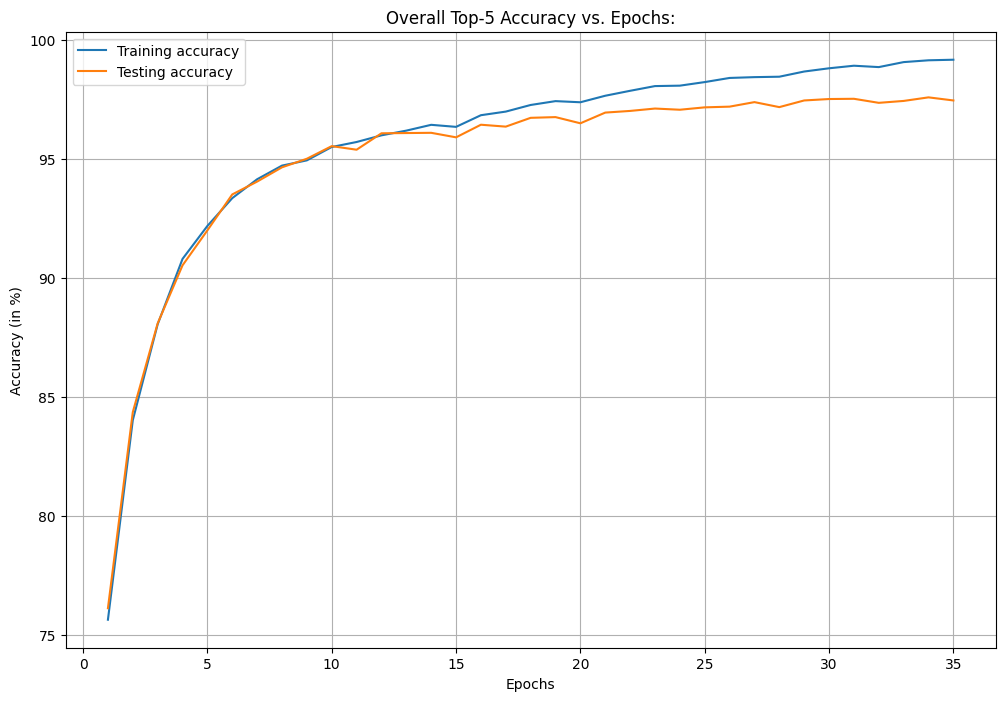
iii. Let us plot a graph to illustrate the progression of training and testing Top-5 accuracy throughout the model training epochs to get insights into its learning and generalization ability.
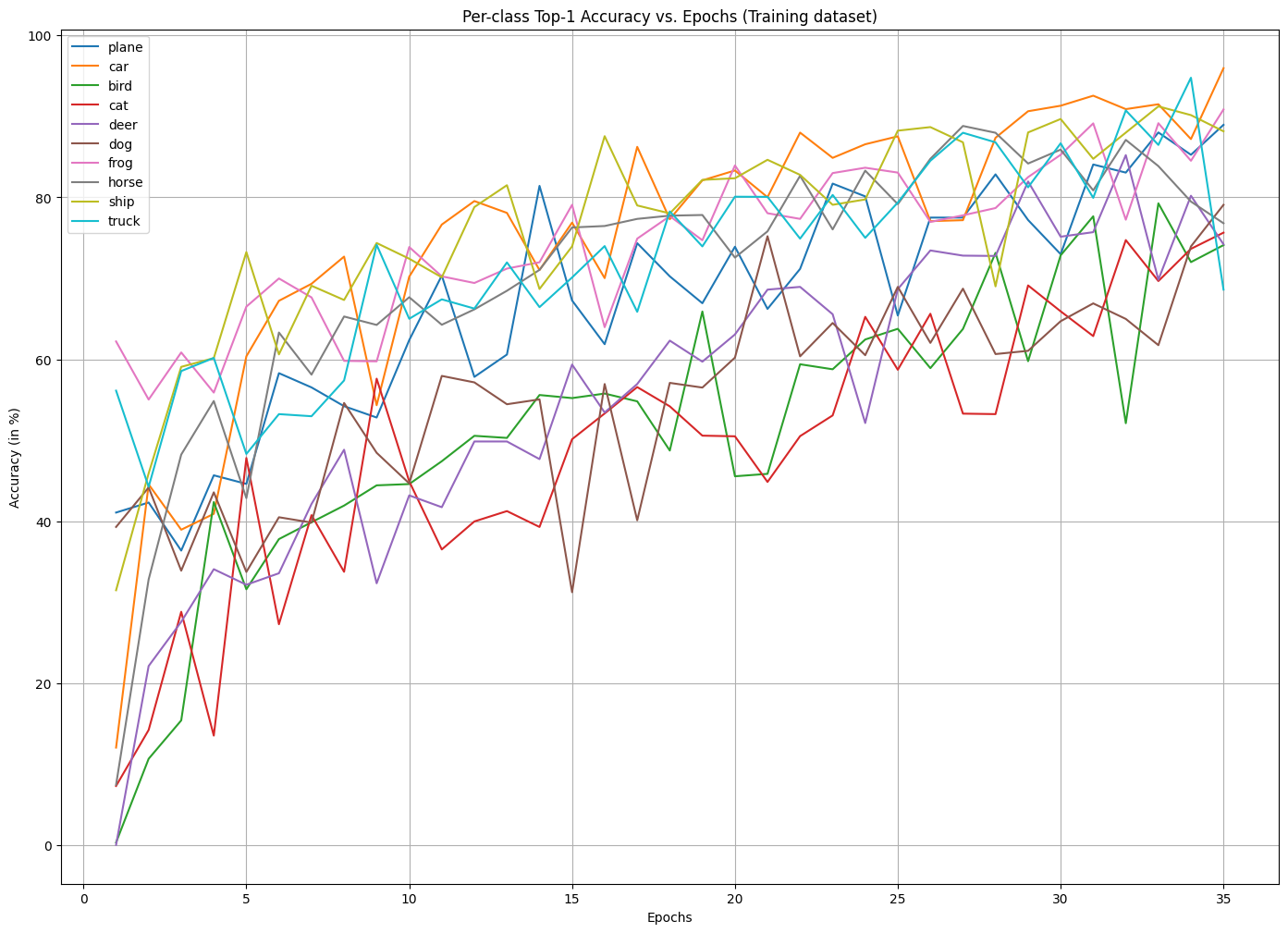
iv. Let us plot a per-class accuracy graph on the training dataset to see the model’s ability to distinguish between specific classes and observe class-specific learning and generalization ability throughout the model training.
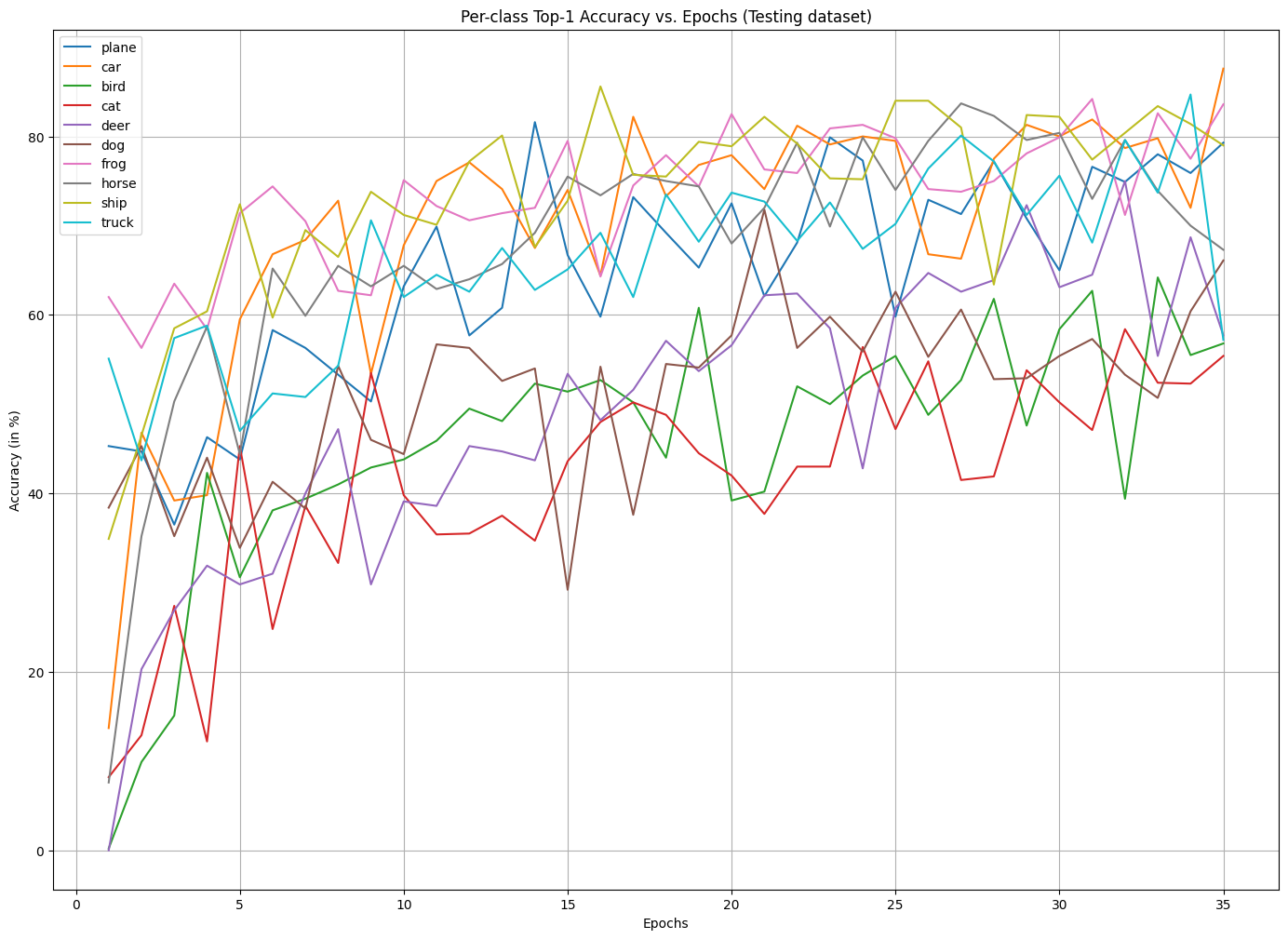
v. Let us plot a per-class accuracy graph on the testing dataset to see the model’s ability to distinguish between specific classes and observe class-specific learning and generalization ability throughout the model training.
9. Load the trained model and predict output on general data
We have obtained the best model with a Top-1 accuracy of 69.02 % at epoch 30. We can load the parameter values of the best saved model back to our current model and perform image classification on a real-world sample images to check whether the prediction will be correct.
After loading the saved model, we shall give an input image to see the model prediction.

The input image belongs to the class: plane
We can observe our model classified the input image to the correct class. Let us give one more input and see the model prediction.

The input image belongs to the class: car
Our model has an accuracy of 69.02 %, and in both cases, it has classified input images to their correct class. But it may not always be true. You can take a sample image and check the model prediction on the best-trained model.
To sum up, the “previous” and current posts illustrate about implementing Convolutional Neural Networks with PyTorch for image classification have covered essential aspects, from CNN architecture to practical PyTorch application, offering a concise guide for building powerful image classification models.
10. References:
- Machine Learning, Tom Mitchell, McGraw Hill, 1997.
- “CS229: Machine Learning” course by Andrew N G at Stanford, Autumn 2018.
Leave a Comment